
Python
(Numpy: random)
Python (Numpy: random)
안녕하세요, 제 블로그는 제가 공부하면서 어려웠던 부분에 대해서 정리하고 공유하는 블로그 입니다.
오늘은 지난번에 했던 poly함수는 잠깐 건너 띄고(나중에 다시 다룰 것입니다.) random함수에 대해서 알아 보겠습니다.
random함수는 built-in(python 자체 내장함수)과 Numpy에 각각 존재 하고 있습니다.
제가 다룰 random은 Numpy내에 있는 random 함수 입니다.
그럼 시작해보겠습니다.
1. randn
code:
numpy.random.randn(d0, d1, ..., dn)
description:
표준정규분포에 따라 random sample을 출력한다.
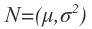
위의 말은 즉슨 실수를 출력할 때 표준정규분포의 값에 따라 숫자를 출력한다는 뜻입니다.
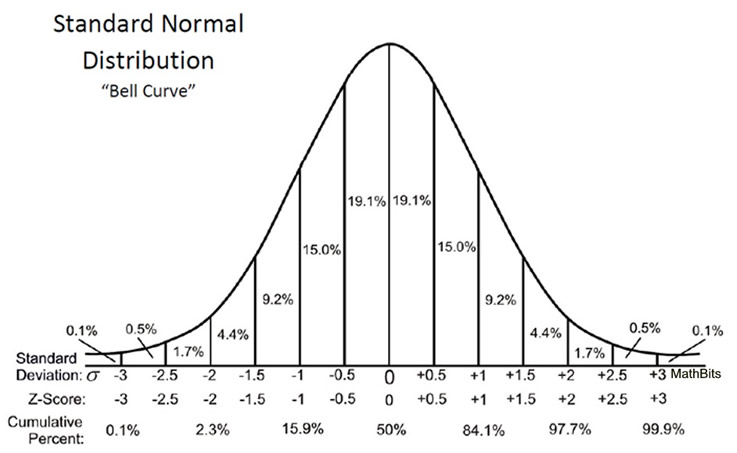
source: https://mathbitsnotebook.com/
예를 들어 0~0.5 사이의 숫자가 나올 확률은 위의 표대로 19.1%가 되고 2~2.5 사이의 숫자가 나올 확률은 1.7%가 되는 것입니다.
한번 결과를 볼까요?
np.random.randn(10)
Out[39]:
array([ 0.35331981, 0.20604435, 0.50329366, 1.65041263, 1.56239592,
-1.48161061, 1.08000842, -0.17272704, 0.72752306, 0.28003827])
np.random.randn(10)
Out[40]:
array([ 0.73091246, 0.35230414, 0.39240512, -0.06545345, 1.09210588,
1.72175495, -0.79059884, -0.48770269, 0.57228939, 1.57846669])
두 번 randn을 사용해보니 0근처의 숫자가 1근처의 숫자보다 더 자주 나오는 것을 알 수 있습니다. 정말 많이 하다 보면 간혹 2가 넘는 경우도 나옵니다.
표준정규분포이다 보니 정규분포로 customizing도 할 수 있습니다.
N(3, 6.25) 인 정규분포는 아래와 같습니다.
2.5*np.random.randn(2,4)+3
Out[45]:
array([[ 0.17539438, 2.58024135, 0.860909 , -1.12025892],
[-1.80527039, 4.97178296, -0.43791976, 1.1660007 ]])
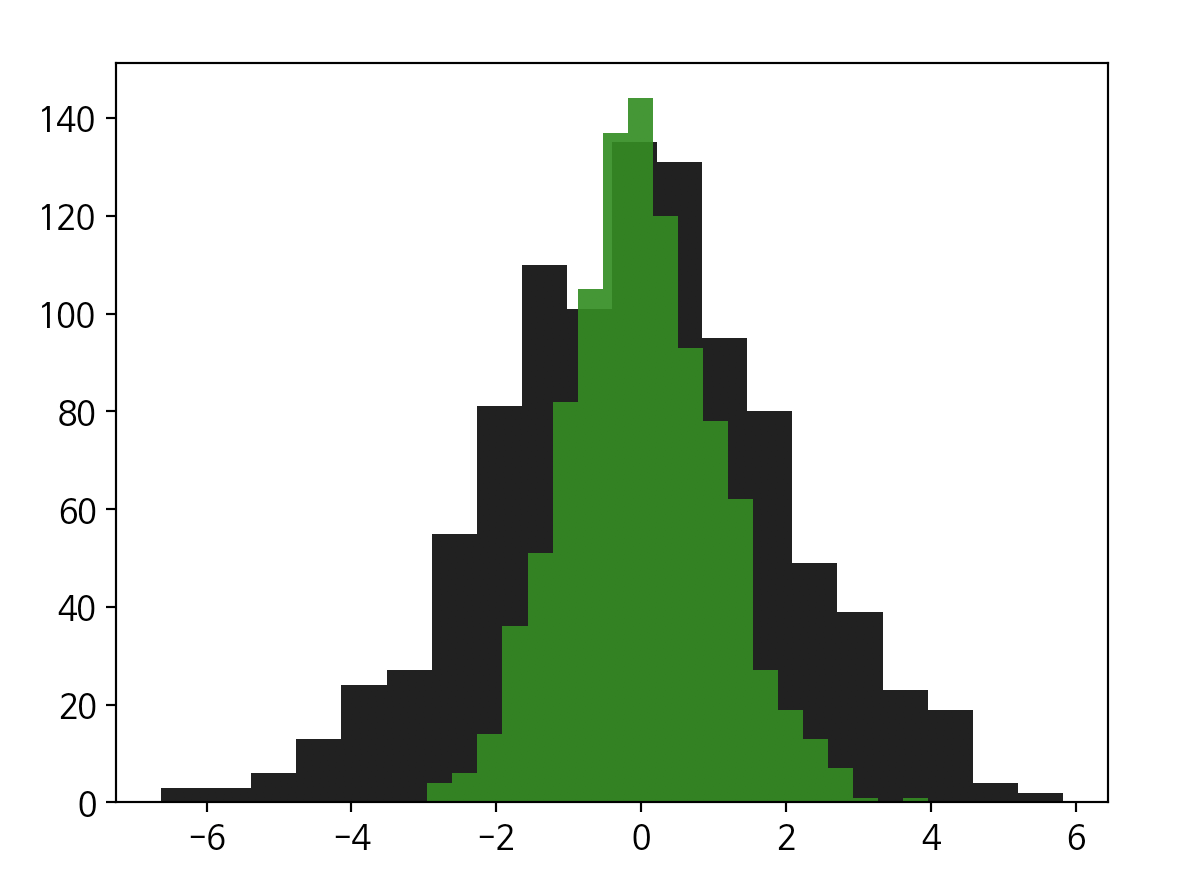
std_dev 이 두배인 경우를 Numpy에서 표현하면 아래와 같습니다.
# std_dev = 2
plt.hist(2* np.random.randn(1000), bins=20, color='k', alpha=0.9)
# std_dev = 1
plt.hist( np.random.randn(1000), bins=20, color='g', alpha=0.9)
출력해보면
2. numpy.random.randint
code:
numpy.random.randint(low, high=None, size=None, dtype='l')
description:
discrete uniform random integer(불연속 균일한 정수) 출력
np.random.randint(2, size=10)
Out[49]: array([0, 1, 1, 1, 1, 1, 0, 0, 1, 1])
np.random.randint(2,5, size=10)
Out[50]: array([2, 3, 2, 2, 3, 3, 3, 4, 4, 3])
np.random.randint(2,5, size=(2,2,2)
)
Out[51]:
array([[[4, 3],
[3, 2]],
[[3, 4],
[2, 2]]])
randn 함수에서는 바로 괄호 안에 array 크기를 넣었던 반면 randint 함수는 size(tuple type)를 따로 지정해줘야 한다.
3. numpy.random.choice
code:
numpy.random.choice(a, size=None, replace=True, p=None)
description:
Generates a random sample from a given 1-D array (1차원 배열에서 랜덤 샘플 출력)
np.random.choice(('apple','pear','grape'), (3,2))
Out[79]:
array([['grape', 'apple'],
['pear', 'apple'],
['grape', 'grape']],
dtype='<U5')
위의 코드를 보면 알수 있듯이 함수의 parameter로 1차원 배열과, 출력할 size 가 기본적으로 들어가야 합니다.
* replace=True는 항상 독립시행이라는 뜻
replace=False로 한번 시험을 해보겠습니다. (1차원 배열의 크기가 출력할 크기보다 크거나 같아야 함)
np.random.choice(('apple','pear','grape','strawberry'),(2,2), replace=False)
Out[87]:
array([['grape', 'strawberry'],
['pear', 'apple']],
dtype='<U10')
np.random.choice(('apple','pear','grape','strawberry'),(2,2), replace=False)
Out[88]:
array([['pear', 'apple'],
['strawberry', 'grape']],
dtype='<U10')
* p=None는 모든 값이 uniform 한 확률로 출력
p를 변화시켜서 값을 출력해보겠습니다.
np.random.choice(('apple','pear','grape','strawberry','orange'),(3,3), p=(0.1,0.05,0.05,0.5,0.3))
Out[101]:
array([['pear', 'strawberry', 'orange'],
['orange', 'strawberry', 'strawberry'],
['strawberry', 'strawberry', 'orange']],
dtype='<U10')
np.random.choice(('apple','pear','grape','strawberry','orange'),(3,3), p=(0.1,0.05,0.05,0.5,0.3))
Out[102]:
array([['grape', 'pear', 'strawberry'],
['pear', 'strawberry', 'strawberry'],
['orange', 'strawberry', 'strawberry']],
dtype='<U10')
p와 1차원 배열의 크기는 같아야 합니다.
더 많은 랜덤함수가 있지만 일단은 여기까지만 보겠습니다. 추후에 더 많이 사용하는 함수가 있다면 공유 드리곘습니다.
